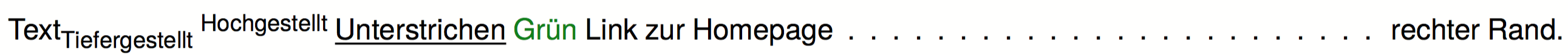speedata Publisher Version 3
Endlich habe ich wieder ein »Major-Release« veröffentlicht. Es ist Zeit für einen kurzen
Rückblick
Wenn man von Version 2.0 ausgeht, sind seit dem ziemlich genau drei Jahre vergangen, in denen es 4 Minor Releases und ca. 150 Patch Releases gab. Das ist durchschnittlich eine Version pro Woche, wobei es natürlich Phasen unterschiedlicher Intensität gab. Interessanterweise kamen bei mir nie Beschwerden aufgrund von Abwärtskompatibilität an, obwohl es kleine inkompatible Änderungen gab (die Betreffen das Cursor-Verhalten bei Objekten, die an den rechten Rand reichen.) Insofern kann ich die umfangreiche Datenbank mit Testfällen als Erfolg ansehen.
Das Entwicklungsmodell ist weitgehend gleich geblieben: Fast alle neuen Features sind Auftragsarbeiten oder Fehlerkorrekturen, die in Kundenprojekten auffallen. In wenigen Fällen kommen Features aus reinem Eigenantrieb. An dieser Stelle ein Dank an die Firmen, die die Entwicklung bezahlt haben.
Seit der Version 2.8 gibt es keine umwälzenden Neuerungen, die meisten Änderungen sind kleine Bugfixes. Ein paar Dinge gibt es doch zu erwähnen:
- Beliebiges Markup in den Daten kann nun mit CSS versehen werden, siehe den eigenen Beitrag dazu
- Base64-kodierte Bilder aus den Daten direkt in den Publisher einfügen (s. Beitrag oben).
- Initialen in Absätzen.
- Belegen von Zellen bei absoluter Positionierung (keine Voreinstellung).
- Neuer Befehl
<Groupcontents>, um den Inhalt einer Gruppe in eine Tabellenzelle einzufügen.
Blick in die Zukunft
Was bringen die nächsten Versionen? Es gibt noch keine feste Roadmap für den speedata Publisher Version 4.
Mein erster Schritt wird sein, das Handbuch fertig zu stellen. Dazu habe ich schon etwas in einem eigenen Beitrag geschrieben. Es fehlt nicht mehr viel. Ein Verlag ist gefunden, das Stichwortverzeichnis muss ich noch fertig stellen und die Bilder überarbeiten. Ich hoffe, dass das zum Ende August abgeschlossen ist. Das Handbuch wird den Publisher in Version 3 beschreiben und ist inhaltlich auf dem aktuellen Stand (fast jedenfalls).
Einer meiner Wünsche ist es, den CSS-Bereich viel stärker auszubauen. Das Thema PrintCSS ist aktuell und wird es sicherlich auch in einigen Jahren noch sein. Mit dem Publisher habe ich aus meiner Sicht die perfekte Grundlage für diese Art von Software geschrieben. Letztendlich ist der Anspruch an die Satzqualität bei PrintCS niedriger als beim Publisher.
Die Liste der Dinge, die ich machen könnte ist nach hinten offen:
- Den XML und den XPath-Parser verbessern
- Die Layoutbeschreibung auch über eine Programmiersprache neben dem XML zugänglich machen (das würde sicherlich etliche Anwender locken)
- Noch stärker in Richtung Textsatz gehen, z.B. Fußnoten verbessern, unabhängige Flows von Texten erlauben etc. Das würde für Verlage interessant sein.
- Tagged-PDF für Barrierefreiheit verbessern
- Docker Image für die einfachere Installation zur Verfügung stellen
- …
Tendenziell wird die Entwicklung, wie oben erwähnt, aber von den Anforderungen getrieben, die ich im täglichen Geschäft habe.
Download
Nicht zu vergessen: Die aktuelle (stabile) Version des Publishers gibt es wie immer unter
Das (alte, aber stets aktuelle) Handbuch unter
https://doc.speedata.de/publisher/de/
Viel Spaß damit! Und nicht zögern, bei Fragen einfach eine mailto:gundlach@speedata.de Mail zu schreiben.