Ende des deutsprachigen Blogs
Dies wird voraussichtlich der letzte Beitrag hier sein. In Zukunft werde ich die Beiträge auf Englisch unter https://news.speedata.de posten, um ein breiteres Publikum zu erreichen.

Dies wird voraussichtlich der letzte Beitrag hier sein. In Zukunft werde ich die Beiträge auf Englisch unter https://news.speedata.de posten, um ein breiteres Publikum zu erreichen.
Die Version 4.14 wurde heute veröffentlicht. Die gerade Zahl am Ende (14) verrät, dass es sich um eine stabile Version handelt, die für eine Zeit lang die offizielle Version sein wird. Nachdem in der letzten Zeit kaum neue Fehler gemeldet wurden, war die Gelegenheit passend, hier ein Release zu erstellen.
Im Vergleich zur Version 4.12 gibt es ein paar kleine Änderungen. (Für den speedata Publisher gilt auch weiterhin, dass alle Änderungen rückwärtskompatibel sind.)
Es ist mal wieder Zeit für ein Update. Sowohl beim speedata Publisher als auch bei boxes and glue hat sich einiges getan. Aber erst eine Ausschau auf die nächsten Veranstaltungen:
Inzwischen habe ich mich für die TUG 2023-Tagung in Bonn registriert (14.–16. Juli). Dort werde ich einen Vortragsvorschlag zu boxes and glue einreichen, hoffentlich wird dieser angenommen. Nicht angenommen wurden meine beiden Einreichungen beim Grazer Linuxtag, teilnehmen werde ich aber dennoch.
Hier hat sich einiges getan. Inzwischen ist die neue Homepage online (https://boxesandglue.dev). Diese ähnelt der alten, als CMS wird aber nun anstelle von Hugo MkDocs mit dem Material for MkDocs Theme benutzt. MkDocs ist leichter erweiterbar und m.E. nicht so undurchsichtig wie Hugo. Mit der neuen Homepage habe ich auch die Dokumentation vorangetrieben. Das PDF Backend (nun mit dem Namen baseline) ist vollständig - bei Bedarf füge ich noch ein paar Beispiele ein. Als nächstes ist das boxes and glue backend dran.
Heute mal etwas mit einem weniger ernsten Hintergrund…
Manche (Grundschul-)Kinder sind im Mathematikunterricht eher gelangweilt und verlangen nach zusätzlichen Rechenaufgaben für zu Hause. Toll ist es natürlich, wenn man dann jemanden kennt, der auf automatisierte Textausgabe spezialisiert ist. Also musste ich mir Übungsblätter mit einfachen Rechenaufgaben überlegen (hier plus und minus).
Die Idee ist, eine Tabelle zu erzeugen, in der per Zufall Werte eingetragen werden. So soll das Ergebnis aussehen:

Damit das ganze etwas kindgerechter wirkt, nehme ich die tolle Schriftart Comic Sans und mache die Kästchen etwas krakelig.
Ich erlaube mir mal wieder auf zwei Tagungen hinzuweisen, an denen ich wahrscheinlich auch Vorträge halten werde: die Grazer Linuxtage im April und die TUG Konferenz in Bonn im Juli:

Anstelle eines Jahresrückblicks (»alles war prima!«) gibt es einen Jahresvorblick bzw. Ausblick auf das Jahr 2023.
speedata Publisher
Die Entwicklung des speedata Publishers beschränkte sich gegen Ende letzten Jahres auf Bugfixes. Nach den größeren Umbauten der letzten Jahre (Harfbuzz-Modus und die Nutzung einer eigenen Lua-Bibliothek anstelle von von LuaJIT) wird die Stabilität insbesondere von Business-Nutzern sehr geschätzt. Durch die Umstellung auf 64-Bit auf allen Plattformen sind nun auch Kataloge mit mehreren tausend Seiten kein Problem mehr. LuaJIT war hier manchmal limitierend.
Für den Anfang diesen Jahres stehen ein paar Dinge im HTML-Bereich an:
Im Rahmen des Pro-Pakets ist die Software-as-a-Service Schnittstelle zum speedata Publisher nun in der Beta-Phase.
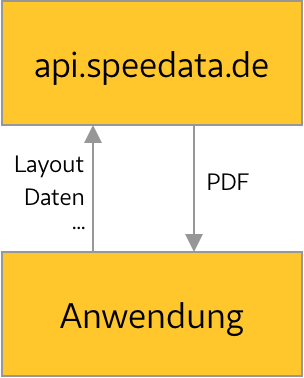
Immer wieder kommt die Frage auf, ob der speedata Publisher auch über das Internet ohne Installation nutzbar ist. Dank der SaaS-API ist das nun möglich. Unter https://api.speedata.de kann per REST-API der speedata Publisher angesprochen werden.
Dazu werden aus einer Anwendung heraus Daten und Layout per HTTP-POST-Request an api.speedata.de gesendet. Anschließend kann das PDF mit einem GET-Request herunter geladen werden.
Das Vorgehen sieht im Prinzip so aus:
Am ersten Oktober wird es eine neue Version vom speedata Publisher geben.
Ich plane, Version 4.12 als regulären Nachfolger von 4.10 (veröffentlicht im Juli) zu veröffentlichen, mit dem Stand der aktuellen Version 4.11.8 und ein paar Patches, die noch nicht eingepflegt wurden wurden.
Es ist mal wieder Zeit für zwei Veranstaltungshinweise.
Die DANTE Sommertagung vom 23.–25. Juni 2022 in Magdeburg (als online-offline Hybridveranstaltung) und
die TUG 2022 Tagung vom 22.–24. Juli 2022 (online)
Auf beiden Konferenzen werde ich das Projekt boxes and glue vorstellen.
Die TUG 2022 Tagung wird von speedata gesponsert. Vielen Dank an die TUG für diese Möglichkeit.
Nach einem halben Jahr gibt es wieder eine neue stabile Version (4.8). Sie steht ab sofort zum Download bereit.
Es gibt nicht viele sichtbare Änderungen, aber dafür wieder mal viele Fehlerkorrekturen (keine Ahnung, wo die ganzen Fehler herkommen - vielen Dank aber an die unermüdlichen Anwender, die mir die Fehler melden.)
Ein paar Anmerkungen trotzdem: