Nach gut einem halben Jahr Entwicklung ist es wieder an der Zeit eine neue Stabile Version (3.2) hochzuladen. Verfügbar ist sie wie immer als fertige Pakete für Mac, Linux und Windows unter https://download.speedata.de/ und als Quellcode auf GitHub.
Neuerungen sind
Viele Fehlerkorrekturen, wie immer (ich bin erstaunt, wie viele Fehler die Anwender so finden, aber meist sind das doch sehr obskure Kombinationen von Eingabedaten…)
Lua basiertes Preprocessing. Eine ausführliche Beschreibung dazu gibt es im Handbuch. Damit kann man vor dem Lauf Daten aus Excel- oder CSV-Dateien lesen und nach XML konvertieren oder Daten mit XSLT umwandeln oder validieren.
ZUGFeRD-Integration. Damit lassen sich Rechnungen im XML-Format an das PDF anhängen, so dass die PDF-Datei und die XML-Datei dieselben Informationen enthalten.
Tabellenausgleich (auf der letzten Tabellenseite bei mehrseitigen Tabellen). Siehe Beitrag hier im Blog.
Schusterjungen und Hurenkinder können nun nicht nur mit yes/no an- und ausgeschaltet werden, sondern mit einer Zahl kann bestimmt werden, wie viele Zeilen zusammen hängend bleiben sollen.
Das neue Handbuch ist in der Distribution enthalten.
Neue Version der TeXGyreHeros-Schriftarten (mit Fehlerkorrekturen und neuen Zeichen).
Neue Eigenschaften des Textformats (tab="hspace") um aus einem Tabulator-Zeichen einen beliebig dehnbaren Zwischenraum zu erzeugen.
Fehlende Zeichen werden angemerkt und erzeugen einen Fehler. Das kann mit reportmissingglyphs="no" bei <Options> ausgeschaltet werden.
Neue Layout- und XPathfunktionen sd:dimexpr() und round().
Setzen von Autor, Titel und anderen Metainformationen möglich.
Span wird (ein wenig) unterstützt, damit kann man farbige Hintergründe erzeugen.
Lange habe ich nach einem halbwegs vernünftigen Workflow gesucht, um mein Handbuch zu erstellen. Inzwischen ist es ja online verfügbar, daher ist es jetzt eine gute Gelegenheit, die benutzten Tools aufzuzeigen. Doch zuvor gibt es ein paar Hintergründe, warum ich diesen Weg gewählt habe.
Notwendige Eigenschaften des Workflows
OpenSource-Tools: alle Komponenten und Konverter müssen frei verfügbar
sein. Das ist mir sehr wichtig, nicht nur, weil ich selber ein großer
Verfechter des OpenSource-Gedankens bin. Vielmehr ist mir wichtig, dass ich
die Dokumentation auf einem Unix-Rechner (Mac, Linux) automatisch erzeugen
lassen kann, ohne Gedanken über die Gültigkeit von Softwarelizensierungen machen zu
müssen.
Verschiedene Ausgabeformate. Zwar ist HTML das Hauptziel, trotzdem möchte
ich in der Lage sein, ein hochwertiges PDF und ggf. auch ein ebook-Format
(z.B. epub) zu erzeugen. Für HTML gibt es ja etliche Werkzeuge, für
hochwertiges PDF aber fast nur LaTeX. (Und falls jemand »dogfooding« in den
Raum wirft: der speedata Publisher ist für Produktkataloge und Datenblätter
etc. aus XML-Quellen spezialisiert, für Handbücher ist das gute alte LaTeX
immer noch das Mittel der Wahl.)
Single-Source Publishing. Also: nur eine Quelle für die Dokumentation haben, nicht mehrere. Was passiert, wenn man mehrere verschiedene Quellen pflegen muss, brauche ich nicht auszuführen.
Die HTML-Ausgabe soll aus mehreren Seiten bestehen. Der Text des Handbuches ist so umfangreich, dass die Benutzerführung arg darunter leiden würde, wäre die HTML-Datei eine lange Seite.
Bequemes editieren von Quelldateien.
Auf den letzten Punkt möchte ich etwas ausführlicher eingehen.
Bequemes editieren von Quelldateien
Das ist natürlich sehr subjektiv, man kann hervorragend darüber streiten, was »bequem« ist. Folgende Eigenschaften hätte ich gerne, damit ich Texte schnell und ohne große Schmerzen bearbeiten kann.
Plain Text Eingabeformat, am besten eine leichte Markup-Sprache wie
Markdown. Ich möchte nicht
zwischen LaTeX oder DocBook-Tags navigieren.
Direkte oder zeitnahe Vorschau. Ich möchte die Änderungen, die ich mache, unmittelbar oder ohne merkliche Verzögerung sehen.
Leichtes Verlinken zu anderen Textteilen.
Unterstützung von Git (Änderungen nachverfolgbar). Mit dem ersten Punkt ist das gegeben.
Ausgangspunkt: das RELAX NG Schema
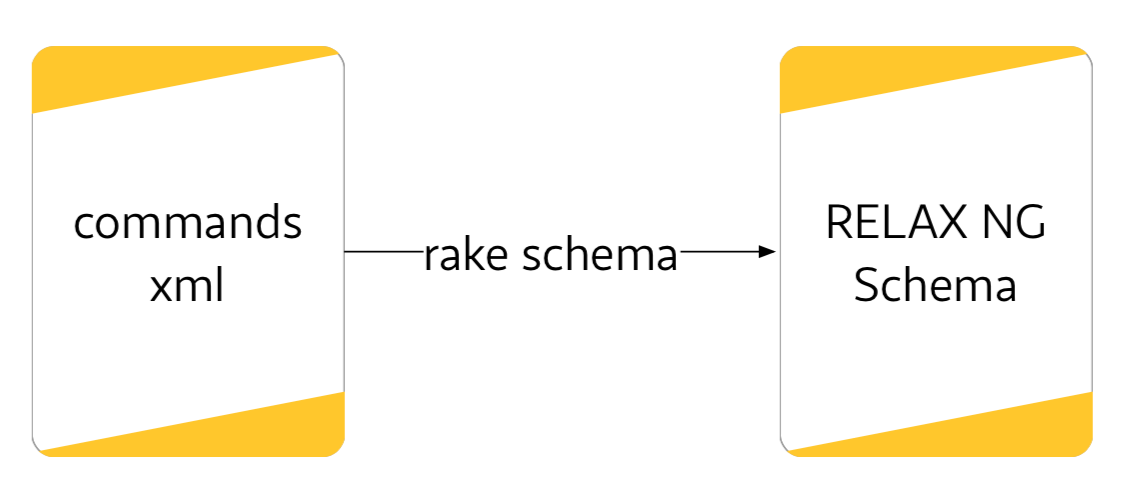
Vorhanden ist die Datei commands.xml, aus der ich das RELAX NG Schema erstelle. Genau genommen sind es zwei, je eines mit deutscher und englischer Beschreibung der Befehle. Den Konverter dazu habe ich in Go geschrieben, weil mir XSLT mit de Saxon doch manchmal viel zu langsam ist…
Mit einem selbst geschriebenen Konverter erzeuge ich aus der commands.xml die RELAX NG Schemadateien. Angestoßen wird der Prozess mit »rake schema« auf der Kommandozeile.
Die Datei commands.xml möchte ich weiterhin als Grundlage für den Referenzteil benutzen, da hier formal beschrieben ist, welche Parameter (Attribute) jeder Befehl haben kann, eine Kurzbeschreibung dazu, ein Beispiel und weiterführende Informationen.
<commanden="AttachFile"since="3.1.1"><descriptionxml:lang="en"><para>Attach a ZUGFeRD file.</para></description><descriptionxml:lang="de"><para>Binde eine ZUGFeRD Datei ein.</para></description><childelements/><attributeen="filename"optional="no"type="text"><descriptionxml:lang="en"><para>The name of the local file to be attached to the PDF.</para></description><descriptionxml:lang="de"><para>Der Name der Datei, die in die PDF-Datei eingebettet werden soll.</para></description></attribute> ...
<examplexml:lang="en"><listing><![CDATA[<AttachFile filename="invoice.xml" description="A ZUGFeRD invoice." type="ZUGFeRD invoice"/>]]></listing></example><examplexml:lang="de"><listing><![CDATA[<AttachFile filename="invoice.xml" description="ZUGFeRD Rechnung" type="ZUGFeRD invoice"/>]]></listing></example><seealso/></command>
Quellformat für das Handbuch
Es liegt nahe, Markdown als Quellformat für die übrigen Teile des Handbuchs zu benutzen. Mit dem statischen
Seitengenerator HUGO zusammen sind die Punkte oben
einigermaßen erfüllt, doch mir fehlen bei Markdown viele semantische
Auszeichnungen wie Indexeinträge, Abbildungsunterschriften, Fußnoten,
Tabellen, Definitionslisten, … Außerdem fehlt mir bei Markdown die formale Strenge,
die ein XML-basiertes Format wie DocBook hat. Aber DocBook-Dateien zu bearbeiten macht nun wirklich nur begrenzt Spaß und erfüllt meine Voraussetzungen (teilweise) nicht.
DocBook als Zwischenformat
Nach langem Suchen und Testen bin ich auf das Format
AsciiDoctor gestoßen, das im Prinzip zwei
Ausgabeformate hat: HTML und DocBook. Das HTML Format hat leider den Nachteil,
dass es immer eine einzige Seite erzeugt. Somit bleibt DocBook übrig. Da man
aus XML mit XSLT leicht andere Formate erzeugen kann, insbesondere wenn diese
wiederum textbasiert sind (wie HTML und LaTeX), ist das für mich die
Lösung der Problem oben.
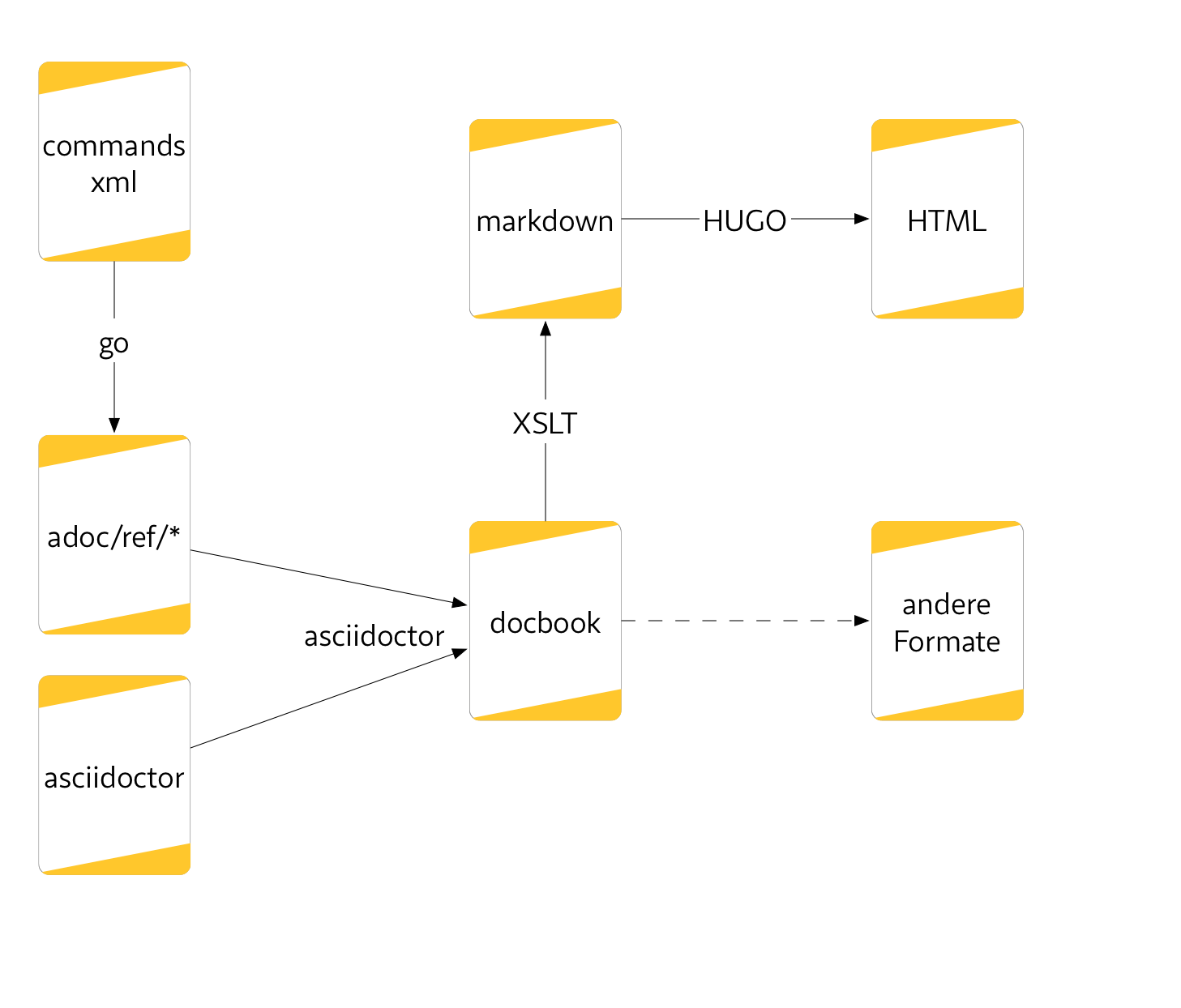
Aus dem Referenzteil »commands.xml« und den handgeschriebenen Seiten wird mit AsciiDoctor die DocBook-Datei. Aus dieser kann man nun alle weiteren Ausgaben erzeugen. HUGO hilft dabei, das Handbuch mit den umfangreichen Designanforderungen zu erzeugen.
Live-Preview während der Eingabe
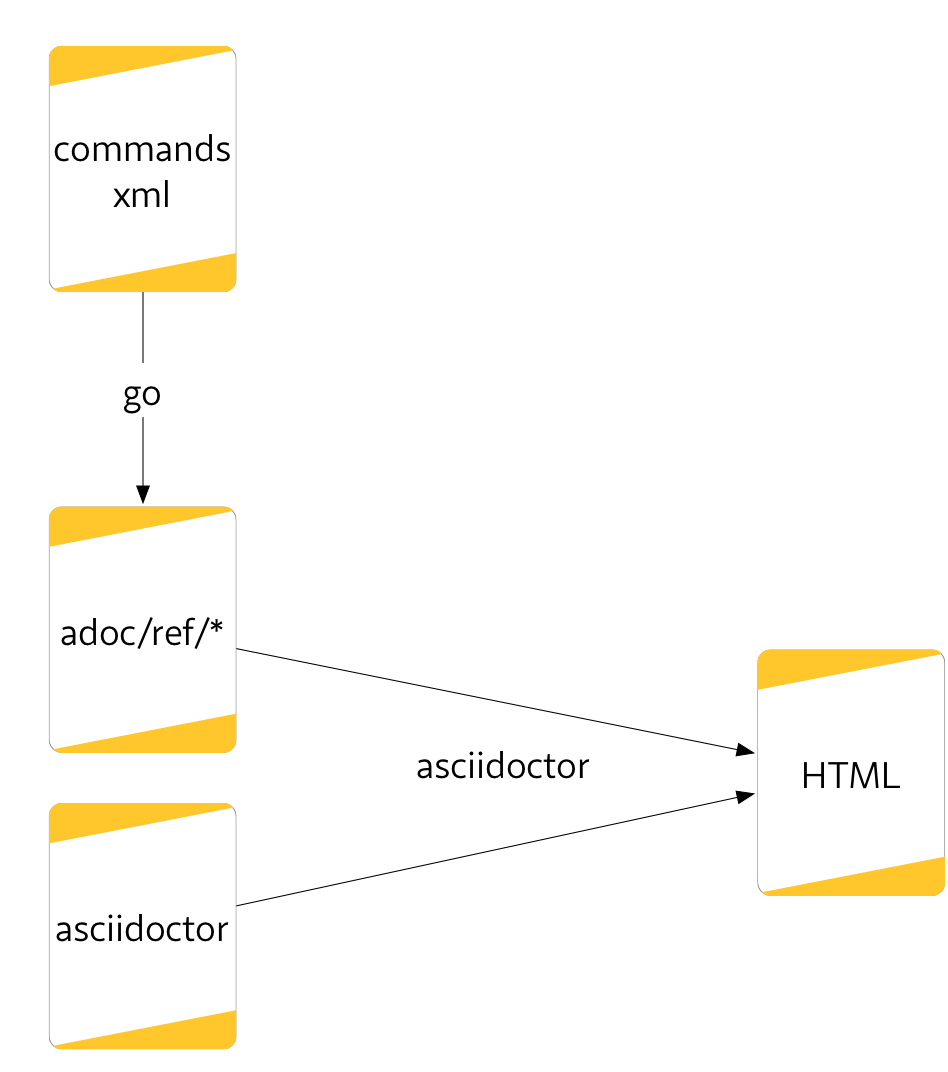
Ich habe oben erwähnt, dass AsciiDoctor auch HTML erzeugt. Das nutze ich, wenn
ich das Handbuch bearbeite. Von HUGO habe ich mir eine Funktionalität geklaut,
die ich sehr praktisch finde. Speichert man im HUGO-Baum eine Quelldatei, so
aktualisiert sich der Browser selbständig. Mit dieser quasi-Live-Vorschau sieht man schnell, ob eine
Formatierung auch richtig angewendet wird. Das habe ich für AsciiDoctor angepasst und so kann ich immer nahezu sofort im Browser sehen, ob alles richtig ist.
AsciiDoctor erzeugt auch HTML, das nutze ich aber nur für die Korrekturschleife des Handbuchs. Die eigentliche HTML-Ausgabe für das fertige Handbuch erfolgt wie oben.
Der Publisher hat (derzeit) noch keine besonderen Fähigkeiten, Aufzählungslisten zu erstellen.
Das liegt auch daran, dass sie sich recht leicht über Textformate nachahmen lassen.
Dafür definiert man ein Textformat mit hängendem Einzug und benutzt das mit dem Text mit den Aufzählungszeichen:
Ich empfehle ja allen Leuten, die ein Layout-Regelwerk bearbeiten wollen, den Oxygen als XML-Editor zu benutzen (die Developer Ausführung reicht). Davon gibt es eine neue Version (Version 20), die Liste der Änderungen gibt es hier:
Ganz frisch (seit Version 3.1.24) gibt es ein neues Feature: Tabellenspalten »ausgleichen«. Damit
lassen sich die Tabellen auf den Seiten ausgleichen. In der Regel benutzt eine Tabelle erst den ersten
Positionierungsrahmen eines Bereichs, dann den nächsten etc.
Es ist mal wieder an der Zeit, die aktuellen Geschehnisse der letzten zwei Monate aufzuschreiben.
Neue Webseite
Lange habe ich1 daran getüftelt, nun ist sie online. Die Seite ist wie gehabt unter https://www.speedata.de zu finden und ist im »neuen« corporate Design. Es folgt dann noch eine englische Übersetzung und dieser Blog, dann war es das soweit mit der Neugestaltung. Die letzte Webseite war noch von Anfang meiner Selbständigkeit und beinhaltete z.B. gar keinen Download-Link… Nun ist alles besser! Und hoffentlich auch einigermaßen übersichtlich.
Die Seite ist wie das Handbuch und diesen Blog übrigens mit Hugo realisiert, eine schicke Software, die statische Webseiten erstellt. Damit spare ich mir die Wordpress-Installation.
Zig neue Versionen des Publishers
Etwas übertrieben, aber einige Versionen sind es schon, hauptsächlich sind es kleine Nettigkeiten, die das Leben mit dem Publisher erleichtern. Ich bereite gerade die Version 3.2 vor, dann wird es auch eine Zusammenfassung der Neuigkeiten geben.
Print-CSS
Das vorletzte Treffen der XUGBER (XML User Group Berlin) war zum Thema Print-CSS. Auf der XMLPrague war das auch mehrfach Thema (sowohl dieses Jahr als auch die letzten Jahre). Ein wenig spiele ich gerade damit herum (https://github.com/speedata/experimental), aber neben dem Tagesgeschäft, mit dem ich meine Brötchen verdiene, komme leider nur zu wenig dazu, das weiterzuentwickeln. Trotzdem macht es Spaß, sich in eine (für mich) neue Technologie einzulesen (und festzustellen, wie bescheuert und einschränkend CSS im Vergleich zum Publisher ist…). Mal schauen, was die nächsten Monate so bringen. Alles noch im pre-alpha Stadium.
Public-Domain Bibeln
Auf Amazon gibt eine Reihe Public-Domain Bibeln, die mit dem Publisher erzeugt wurden. Derzeit sind nur lateinische Sprachen verfügbar, demnächst aber hoffentlich auch Arabisch und andere rechts-nach-links-Sprachen.
Auch dieses Jahr gibt es wieder ein Hands-on Workshop in Prag zum speedata Publisher.
Der Workshop-Tag ist wieder der erste Tag der Konferenz. Noch ist der genaue Plan nicht online, dafür aber eine Liste aller Sessions.
Das neue Handbuch ist nun online.
Ein Grund zum Feiern: es hat etwa ein Jahr gebraucht von den ersten Texten bis zum aktuellen Status.
Derzeit ist es nur auf Deutsch verfügbar, eine englische Version wird bald in Angriff genommen (kennt jemand einen guten Übersetzer für technische Dokumente?).
In der Distribution ist bis zur Übersetzung noch das alte Handbuch enthalten, das zwar immer noch aktuell, aber nicht so ausführlich ist.
Ein paar Neuerungen gegenüber dem alten Handbuch:
Volltextsuche
Ausführlicher (das neue Handbuch hat viele Beispiele, Bilder und How-Tos, die Reihe »Feature der Woche« ist im Handbuch aufgegangen)
Auf Mobilgeräten nutzbar (responsive Design)
Mit viel Liebe zum Detail gestaltet (Syntax Highlighting, leichte Navigation, …)
Demnächst gibt es an dieser Stelle ein paar Sätze zum Workflow. Nur soviel: der Text ist in Asciidoctor geschrieben, wird nach DocBook konvertiert und dann per XSLT nach Markdown und anschließend mit Hugo in eine Webseite umgewandelt.
Das hört sich kompliziert an, aber dank Automatisierung geht alles wunderbar einfach. Irgendwann bestimmt auch auf Github verfügbar.
Dazu haben wir eine Eintrittskarte (Full pass) zu verschenken! Wer die Karte haben möchte, möge sich
melden, entweder per E-Mail oder per Kommentar hier (oder per Twitter).
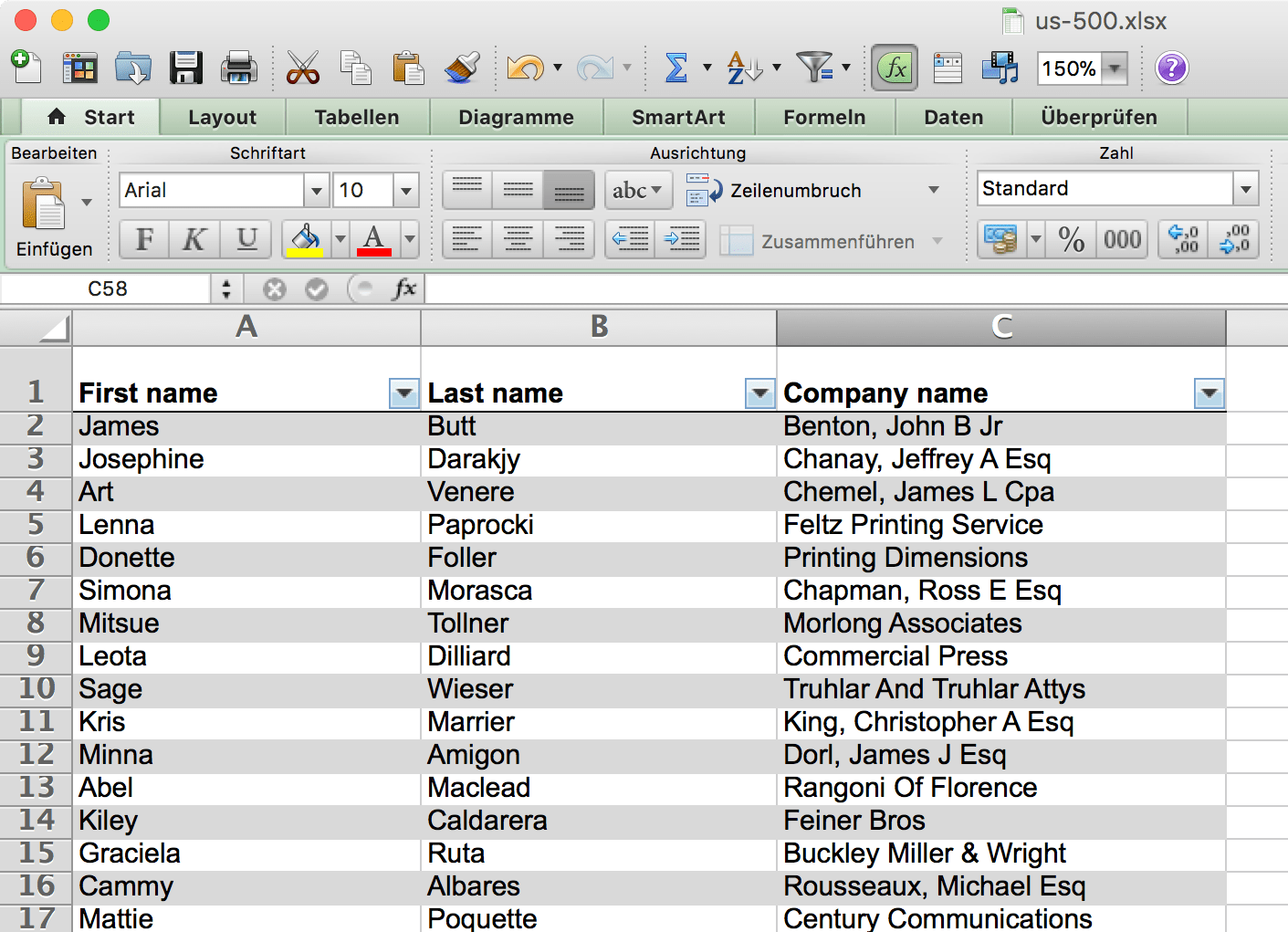
Im letzten Beitrag habe ich schon
erwähnt, dass der Publisher nun Excel-Dateien lesen und nach XML konvertieren
kann. Somit eignet sich der speedata Publisher als »Excel nach PDF« Konverter.
Das einzige, das man machen muss, ist eine kleine Prozedur schreiben, die die Daten bestimmten XML-Knoten zuweist.
Excel-Dateien lesen
Der erste Schritt für die Ausgabe von Excel-Dateien, diese einzulesen.
Es muss eine Lua-Datei erzeugt werden (z.B. xl2pdf.lua), die folgenden Aufbau hat:
spreadsheet, err = xlsx.open(".....xlsx")
ifnot spreadsheet then print(err)
os.exit(-1)
end
mit dem spreadsheet-Objekt kann man auf die einzelnen Arbeitsblätter zugreifen:
-- Die Anzahl der Arbeitsblätter kann man mit dem # operator (#spreadsheet) erhalten.ws = spreadsheet[1]
ifnot ws then os.exit(-1)
end
Nun kann man mit ws(x,y) auf die Zelle x,y zugreifen, wobei 1,1 die erste Zelle oben links ist. Die Größe des Arbeitsblattes ist in den Variablen ws.minrow, ws.maxrow und ws.mincol, ws.maxcol enthalten.
Und die XML-Daten schreiben
Die XML-Daten kann man über die Schnittstelle xml.encode_table(data) erzeugen. Wenn z.B. ein rechteckiger Bereich einfach als XML geschrieben werden soll, dann kann folgender Code benutzt werden:
local data = {}
local row, cell
data._name ="data"for y=ws.minrow,ws.maxrow do row = {}
row._name ="row"for x=ws.mincol,ws.maxcol do cell = {}
cell._name ="cell" cell[1] = ws(x,y)
row[#row +1] = cell
end data[#data +1] = row
endok, err = xml.encode_table(data)
ifnot ok then print(err)
os.exit(-1)
end
Die Ausgabe ist wieder wie bei dem CSV2PDF converter: