Das Feature der Woche fällt diese Woche leider aus. Letzte Woche war ich im
Urlaub und diese Woche steht der Umzug ins neue Büro an. Und wenn jetzt jemand
sagt, »das hättest du auch vorbereiten können«, dann hat er natürlich recht.
Im Moment passiert recht viel im Hintergrund. Neben den erwähnten neuen
Büroräumen (Reichsstraße 92A in Berlin), die erst einmal neu eingerichtet
werden wollen, gibt eine Veranstaltung, auf die ich hinweisen möchte. Der
OpenSource Day findet am 23. November
2016 statt. Hier werde ich vor Ort sein und auch die Gelegenheit für einen
kurzen Pitch haben. Die Veranstaltung findet in der c-base statt, eine gute
Gelegenheit diesen Ort mal kennen zu lernen.
Weiterhin bin ich gerade dabei, die nun wirklich in die Jahre gekommene
Webseite zu überarbeiten. Bis diese fertig gestellt ist, wird es aber noch
etwas dauern, weil dazu noch etliche Dinge zu erledigen sind. (Außerdem wartet
ja auch die tägliche Arbeit…)
Ebenfalls bin ich gerade dabei, die »mini-GmbH« in eine »echte« GmbH zu
wandeln. Das habe ich schon länger vor, nun will ich den Prozess endlich bis
Jahresende abschließen.
Und last but not least steht auch langsam mal die Veröffentlichung der Version 3 ins Haus. Ich erwarte keine großartigen Änderungen mehr. Ich will die Software noch ein wenig »reifen« lassen. Dann habe ich eine wirklich stabile Version 3 (mit ein paar nicht rückwärtskompatiblen Änderungen).
In der 20. Ausgabe der Reihe »Feature der Woche« (Jubiläum!) geht es um Schneidemarken (Schnittmarken) und um
Beschnittzugabe. Ob Schneidemarken in der heutigen digitalen Druckwelt
überhaupt noch eine Notwendigkeit haben, vermag ich nicht zu beurteilen. Man kann sie mit
<Optionscutmarks="yes"/>
einschalten. An allen vier Ecken gibt es nun zwei Striche, die das Endformat
(z.B. DIN A4) anzeigen. Die Striche gehen nicht bis ganz zur Schnittkante,
damit noch ein wenig »Spiel« ist, wenn das Blatt nicht exakt zugeschnitten
wird. Beim Druck wird oft nicht nur eine Seite auf ein Blatt gedruckt,
sondern viele Seiten auf einen Bogen. Mit den Schneidemarken können nun die
Seiten passend ausgeschnitten werden. (Eine Google Bildersuche ist sehr erhellend.)
Linke obere Schneidemarke. Das Endformat (TrimBox) ist grün markiert
Beschnittzugabe / Anschnitt
Verwandt mit dem Thema der Schnittmarken ist die Beschnittzugabe (auch: Anschnitt, engl.
bleed). Sie kennzeichnet einen Bereich rund um das Endformat, in den sichtbare
Objekte im Endformat, die an den Rand stoßen, in den Rand hineinragen sollen.
Das klingt kompliziert, ist aber ganz einfach:
Bild ohne und mit Beschnittzugabe. Das Endformat (TrimBox) ist grün markiert. Mit negativen Längenangaben bei padding kann man den gezeigten Effekt erreichen.
In beiden Fällen wird das Papier (sofern es gedruckt wird) am grünen Rahmen
abgeschnitten. In der Praxis treten aber im Druck und dem anschließenden
Beschnitt kleine Ungenauigkeiten auf so dass der Schnitt nicht unbedingt exakt an
der Kante des Bildes ist. Ist der Schnitt ein wenig zu weit vom Bild entfernt, sieht
man im Ergebnis einen unschönen kleinen weißen Streifen. Um das zu vermeiden,
schiebt man das Bild etwas in den Rand (Anschnitt) hinein und stellt sicher,
dass immer »im Bild« ausgeschnitten wird. Wie groß die Beschnittzugabe ist, kann im Publisher eingestellt werden:
<Optionsbleed="3mm"/>
Die Voreinstellung ist 0.
Zwei Dinge werden durch diese Angabe erreicht: zum einen wird der Anschnitt im
PDF markiert (die BleedBox, im Beispiel oben blau dargestellt), so dass die
weiter verarbeitende Software dies automatisch erkennt. Zweitens wird für manche Befehle (derzeit wird nur Box unterstützt) die Option bleed="..." nützlich.
<Boxwidth="5"height="2"bleed="left"/>
Die Box wird dann um die passenden Ausmaße vergrößert, ohne, dass man noch etwas rechnen muss.
Dieser Artikel bezieht sich auf den speedata Publisher in der Version 2.7.7. Andere Versionen haben womöglich andere Befehle oder die genannten Befehle zeigen ein anderes Verhalten. Bitte schau im Zweifelsfall in der Anleitung nach.
In der Serie »Feature der Woche« beschreibe ich einmal in der Woche mehr oder weniger nützliche Eigenschaften des Publishers. Kommentare gerne an mich per E-Mail oder einfach im Kommentarfeld.
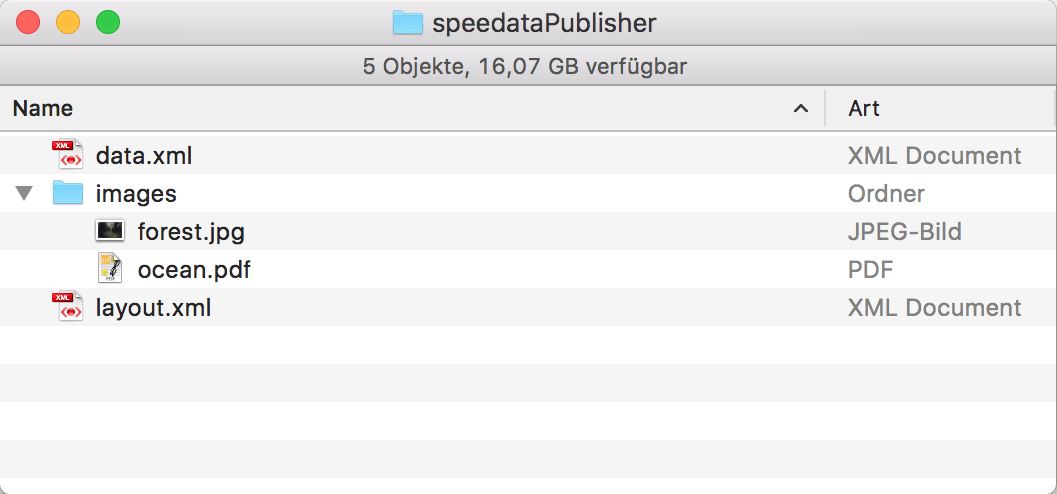
Diese Woche geht es ganz abstrakt um »Dateiorganisation«. Wo müssen die Bilder
gespeichert sein, die im Dokument verwendet werden, wie muss die Datendatei
heißen?
Wenn der Publisher startet, wird das aktuelle (Arbeits-)Verzeichnis und alle Kindverzeichnisse eingelesen und die Dateinamen gespeichert. Sobald eine Ressource geladen wird (Schriftdatei, Bilddatei) wird in dieser Liste nachgeschaut, ob eine entsprechende Datei existiert. Dabei wird nicht unterschieden, in welchem Verzeichnis die Datei liegt. Daraus folgt:
Wenn während des Laufs sich etwas im Dateisystem ändert, bekommt der Publisher davon nichts mit
Es ist egal, wie die Verzeichnisse heißen. Die Bilder können, müssen aber nicht, im Verzeichnis mit dem Namen »bilder« speichert sein.
Wenn das Arbeitsverzeichnis zu groß ist, ist der Startvorgang langsam. Einige Tausend Dateien im Arbeitsverzeichnis sind in der Regel kein Problem, aber irgendwann wird es zu langsam.
Es gibt Ausnahmen von der Regel:
Man kann mit sp --no-local den Publisher anweisen, das Arbeitsverzeichnis nicht rekursiv zu durchsuchen.
Mit --extra-dir kann man ein Verzeichnis hinzufügen, das rekursiv durchsucht wird (das Argument kann mehrfach angegeben werden, um weitere Verzeichnisse einzubinden.).
Mit sp --systemfonts wird für Schriftdateien auch in Verzeichnissen gesucht, die vom System vorgegeben sind.
Mit sp --wd DIR kann ein Verzeichnis angegeben werden, das zum Arbeitsverzeichnis wird (es wird ein cd DIR vor dem Lauf ausgeführt).
Welche Namen müssen die Datendatei und die Layoutdatei haben?
Der speedata Publisher sucht das Layout mit dem Namen layout.xml und die
Datendatei mit dem Namen data.xml. Beide lassen sich auf der Kommandozeile
(--layout=XYZ und --data=XYZ) und in der Konfigurationsdatei anpassen
(layout=XYZ und data=XYZ).
Mögliche Dateiorganisation in einem Verzeichnis. Der Name der Unterverzeichnisse (Ordner) ist beliebig.
Dieser Artikel bezieht sich auf den speedata Publisher in der Version 2.7.5. Andere Versionen haben womöglich andere Befehle oder die genannten Befehle zeigen ein anderes Verhalten. Bitte schau im Zweifelsfall in der Anleitung nach.
In der Serie »Feature der Woche« beschreibe ich einmal in der Woche mehr oder weniger nützliche Eigenschaften des Publishers. Kommentare gerne an mich per E-Mail oder einfach im Kommentarfeld.
Das Bild _samplea.pdf ist (wie _sampleb.pdf) Bestandteil des Publishers
und für Testzwecke gut nutzbar. Als Bildformate sind PDF, PNG und JPEG
möglich. Andere Formate müssen vor der Verarbeitung in eines dieser Formate
konvertiert werden. Das Format, das in der Praxis am wenigsten Probleme
bereitet ist PDF. Hier können auch Farbprofile eingebettet werden.
Die Bilder
werden bei der Verarbeitung im Publisher nicht verändert, das heißt, sie
behalten unter anderem ihre ursprüngliche (Datei-)Größe bei. Bei sehr großen
Bildern ist die Verarbeitungsgeschwindigkeit geringer und die Größe der
resultierenden PDF-Datei nimmt natürlich zu. Daher kann es sich lohnen, für
die Verarbeitung spezielle Versionen mit kleineren Dateigrößen bereit zu
halten.
Breite und Höhe der Bilder
Wenn man Bilder einbindet, dann ist es immer sinnvoll, eine Größenangabe
mitzugeben. Ansonsten wird die natürliche Größe des Bildes genommen. Was die
natürliche Größe ist, ist nicht immer eindeutig zu sagen. In der Regel gibt es
in der Bilddatei eine DPI-Angabe. Die ist aber oftmals willkürlich vom
Bildbearbeitungsprogramm gesetzt (EXIF Felder). Wenn dort beispielsweise 72
DPI steht, ist ein 720 Pixel breites Bild 10 Zoll breit. Bei 300 DPI wäre das
nur 2,4 Zoll.
Da man sich aber auf die Angabe nicht verlassen kann, werden Größenangaben für
die Ausgabe benötigt. Das kann entweder die gewünschte Höhe des Bildes oder
die gewünschte Breite des Bildes sein, oder beide Angaben zusammen. Im
Beispiel oben hat das Bild eine Breite von fünf Zentimeter. Die Angabe kann
natürlich auch als absolute Angaben in Rasterzellen gemacht werden. Ebenso
verhält sich die Angabe einer Höhe. Die Angabe von 100% bedeutet, dass die
gesamte verfügbare Breite genutzt werden soll (derzeit – Version 2.7.4 –
werden andere Prozentangaben noch nicht unterstützt). Die Angabe auto ist
wie das Weglassen der Angabe und ergibt keinen Sinn (außer, dass das
kompatibel zu CSS ist).
Wenn beide Proportionen angegeben sind (Breite und Höhe) gibt es zwei Modi:
Beibehalten des Seitenverhältnisses oder Strecken bzw. Stauchen der Ausgabe.
Ist clip auf 'yes' gesetzt, wird nur ein Ausschnitt gezeigt.
Die Größe von Bildern kann man mit den beiden XPath-Funktionen
sd:imagewidth(<Dateiname>) und sd:imageheight(<Dateiname>) ermitteln. Das
Ergebnis ist in Rasterzellen. Vorsicht, hier wird die natürliche Größe
genommen, die gegebenenfalls ohne Aussagekraft ist.
Maximale Höhe und Breite, minimale Höhe und Breite
Um die natürliche Größe zu benutzen, aber Einschränkungen anzugeben, gibt es die vier Kombination aus min/max und width/height. Das Bild in dem folgenden Beispiel wird nicht breiter als 10 Rasterzellen und nicht höher als 3. Das Seitenverhältnis bleibt erhalten:
Das Bild ist auf die Höhe von drei Rasterzellen beschränkt.
Drehen von Bildern
Mit dem Attribut rotate kann man Bilder in 90 Grad Schritten drehen
(positive Werte: im Uhrzeigersinn). Das nachfolgende Beispiel dreht ein Bild
um 90 Grad gegen den Uhrzeigersinn, wenn es sich um ein Hochformat-Bild
handelt. Mit dem XPath-Befehl sd:aspectratio(<Dateiname>) kann man das
Seitenverhältnis eines Bildes ermitteln. Wenn es größer als 1 ist, dann
handelt es sich um ein Bild im Querformat.
<Layoutxmlns:sd="urn:speedata:2009/publisher/functions/en"xmlns="urn:speedata.de:2009/publisher/en"><Recordelement="data"><ForAllselect="img"><PlaceObject><Imagefile="{@file}"width="5"rotate="{if ( sd:aspectratio(@file) < 1 ) then '-90' else '0'}"/></PlaceObject><NextRow/></ForAll></Record></Layout>
wird das zweite Bild um 90° gegen den Uhrzeigersinn gedreht. Die geschweiften
Klammern bei file und rotate bedeuten, dass in den XPath-Modus gesprungen
wird, um die Ausdrücke auszuwerten.
Achtung: ist das Bild im Argument von sd:aspectratio() nicht im Dateisystem vorhanden, wird der Wert von dem Platzhalterbild genommen. Um zu überprüfen, ob ein Bild überhaupt vorhanden ist, kann man den Befehl sd:file-exists(<Dateiname>) benutzen.
Speicherort der Bilddateien
Meist liegen die Bilder im Dateisystem oder in einem DAM (digital asset management). Im Dateisystem können sie entweder mit einem absoluten Pfad angesprochen werden:
<Imagehref="file:///Pfad/zum/Bild.pdf"/>
oder als Datei in einem der Unterverzeichnisse des Suchpfads. Beispielweise können die Bilder in dem Unterverzeichnis images liegen:
Mögliche Dateiorganisation in einem Verzeichnis. Der Name der Unterverzeichnisse (Ordner) ist beliebig.
Die Bilder können auch mittels http-Protokoll von einem Webserver geladen werden. Die Syntax ist analog zum Beispiel mit dem absoluten Pfad:
Derzeit (Version 2.7.4) wird das https-Protokoll (SSL) nicht unterstützt.
Bild nicht gefunden?
Was passiert, wenn ein Bild nicht gefunden wird? Das normale Verhalten ist die Ausgabe einer Fehlermeldung und einem Platzhalterbild, das das Fehlen anzeigt:
Man kann auch noch einstellen, ob es ein Fehler ist, wenn ein Platzhalterbild ausgewählt wird, oder nur eine Warnung.
<Optionsimagenotfound="error"/>
bzw. warning für eine Warnung.
Besonderheiten bei PDF-Dateien
PDF-Dateien haben einige Besonderheiten: sie können mehrere Seiten enthalten und die einzelnen Seiten haben verschiedene Boxen, die den sichtbaren Bereich und andere Bereiche markieren. Manche der Boxen sind für den Ausdruck wichtig, manche für die Ansicht im PDF-Anzeigeprogramm. Die Box, die mit den angegebenen Größen angezeigt werden soll, wird mit dem Attribut visiblebox (bis Version 2.7.5: maxsize) bestimmt:
bedeutet, dass die »artbox« in der Größe 210mm × 297mm dargestellt wird.
Das Attribut page wurde schon in Feature der Woche: Mehrseitige PDF
einbinden vorgestellt. Er
dient dazu, die Seite auszuwählen, wenn eine PDF-Datei eingebunden wird. Mit
sd:number-of-pages(<Dateiname>) kann ermittelt werden, wie viele Seiten eine
PDF-Datei enthält.
Weitere Parameter
Man kann über die padding-*-Angaben festlegen, wie viel Abstand das Bild vom entsprechenden Rand haben soll.
Mit dipwarn kann eine Warnung herausgegeben werden, wenn die tatsächliche Anzahl der Pixel je Zoll geringer ist, als die Vorgabe.
Dieser Artikel bezieht sich auf den speedata Publisher in der Version 2.7.4. Andere Versionen haben womöglich andere Befehle oder die genannten Befehle zeigen ein anderes Verhalten. Bitte schau im Zweifelsfall in der Anleitung nach.
In der Serie »Feature der Woche« beschreibe ich einmal in der Woche mehr oder weniger nützliche Eigenschaften des Publishers. Kommentare gerne an mich per E-Mail oder einfach im Kommentarfeld.
Nicht immer klappt die Textausgabe, wie sie soll. Manchmal sind Objekte zu
breit, manchmal wird das falsche Textformat genommen und gelegentlich sieht
die Tabelle nicht so aus, wie sie eigentlich sollte. Damit die Fehlersuche
nicht zu schwierig wird, gibt es im speedata Publisher diverse Hilfen. In Version 2.7.4 wurde der Befehl Trace eingeführt, der verschiedene Schalter beinhaltet. Derzeit sind dies (mit Voreinstellung):
Im Beitrag Feature der Woche: Schriftarten einbinden bin ich schon auf die Textauszeichnung (Fett, Kursiv, …) eingegangen, möchte das aber an dieser Stelle wiederholen, weil es immer wieder Fragen aufwirft.
Um einen Text zum Beispiel kursiv zu setzen, klammert man den Text (Value) mit I ein:
Der Publisher wird in Version 3 (auf die ich gerade hin arbeite) zu den älteren Version inkompatible Eigenschaften haben:
Das Regelwerk gibt es nur noch auf Englisch, die deutschsprachige Variante fällt weg
Das Verhalten bei PlaceObject, wenn der rechte Rand des Objekts auf den rechten Rand der Seite fällt, ist nun wie folgt: der virtuelle Cursor wird dann auf die nächste Zeile in Spalte 1 gesetzt. Folgender Code zeigt die Änderung (siehe Fehler #105):
Diese Woche gibt es einen Auszug aus dem Handbuch. Da das Thema mehr
Beachtung bekommen soll, gibt es dafür einen eigenen Beitrag
Um zu gewährleisten, dass neue Versionen des Publishers auch exakt
dieselben Ergebnisse liefern wie vorhergehende, hat der Publisher eine
Funktionalität eingebaut, mit der man unerwünschte Verhaltensänderungen
erkennen kann.
Die Idee ist folgende: ausgehend von einer Layout-Datei und einem
überprüften Ergebnis (Referenz PDF) kann der Publisher kontrollieren, ob
mit der aktuellen Version noch immer dasselbe Ergebnis erzielt wird.
Dazu erstellt man eine Layoutdatei und Datendatei im XML Format, lässt
eine PDF Datei daraus erzeugen und speichert diese unter dem Namen
reference.pdf ab. Bei dem Aufruf von sp compare <Verzeichnis> wird
nun der Publisher erneut aufgerufen und prüft visuell, Seite für Seite,
ob die resultierende Datei mit der vorher angelegten PDF Datei
reference.pdf übereinstimmt.
Voraussetzungen für den Vergleich
Der Publisher sucht rekursiv ausgehend von dem angegebenen Verzeichnis
nach Verzeichnissen, die eine Datei layout.xml oder eine Datei
publisher.cfg enthalten. In diesem Verzeichnis wird dann ein
Publisher-Durchlauf gestartet. Die Layoutdatei muss unter dem Namen
layout.xml, die Daten-Datei unter dem Namen data.xml zu finden sein,
falls das nicht in der (optionalen) Datei publisher.cfg anders
konfiguriert ist.
Der PDF-Vergleich benötigt eine Installation der kostenfreien
Programmbibliothek ImageMagick, die skriptbasiert Bilder manipulieren
und vergleichen kann. ImageMagick gibt es unter anderem für die
Betriebssysteme Windows, Mac und Linux.
Vorgehensweise
Ausgehend von einer Layout und einer Datendatei erzeugt man in gewohnter
Weise eine PDF Datei. Am einfachsten ist es, wenn sie direkt unter dem
Namen reference.pdf erscheint.
sp --jobname reference
erzeugt die passende PDF-Datei. Mit
sp --jobname reference clean
löscht man die übrigen und nicht weiter benötigten Zwischendateien. Das
Verzeichnis sieht nun so aus:
Die Dateien source.png und reference.png (bzw. bei mehreren Seiten
mit einer Kennung für die Seitenzahl) enthalten die aktuelle Version und
die Referenz als Grafik. Die Datei pagediff.png (auch hier mit
Kennungen für die Seitenzahlen) stellt die Unterschiede zwischen den
ersten beiden Dateien hervorgehoben dar. Die Gemeinsamkeiten werden
abgeschwächt dargestellt.
Qualitätssicherung
Mit den Möglichkeiten des PDF-Vergleichs kann man nun eine Sammlung von
Beispieldokumenten erstellen, die produktionstypisch sind. Eine
Vorgehensweise besteht darin, eine Verzeichnisstruktur zu erstellen, die
wie folgt aufgebaut ist:
Mit dem Aufruf sp compare qa werden alle Unterverzeichnisse
durchlaufen und überprüft. Im besten Fall ist die Ausgabe:
$ sp compare qa/
Total run time: 4.541458s
In der Serie »Feature der Woche« beschreibe ich jeden Montag mehr oder weniger nützliche Eigenschaften des Publishers. Kommentare gerne an mich per E-Mail oder einfach im Kommentarfeld.
Das Einbinden von Schriftarten in den gängigen Formaten ist sehr einfach.
Unterstützt werden die Formate Type1 (Dateien .pfb und .afm) sowie
TrueType und OpenType (Dateien .ttf und .otf). TrueType collections sind
prinzipiell möglich, aber noch nicht freigeschaltet (hier hätte ich gerne ein
paar Testfälle).
Um dem Publisher Schriftarten bekannt zu machen und zu nutzen, sind
zwei Schritte notwendig. Der erste Schritt ist das Laden einer
Schriftdatei:
Wie im letzten Post (Feature der Woche »Silbentrennung«) schon angedeutet, gibt es hier eine
Zusammenfassung, wie die Silbentrennung in TeX (und damit auch im
speedata Publisher) funktioniert. Detailliert ist sie in Franklin Liangs
Dissertation »Word Hy-phen-a-tion by Com-put-er« nachzulesen (zu finden auf
der Seite der TUG).
Der Trennalgorithmus funktioniert statisch, das heißt, jedes Wort wird gleich
getrennt, egal wo es in einem Satz vorkommt oder welche Bedeutung es hat. So
wird nicht zwischen Staub-ecken und Stau-becken unterschieden. Grundlage für
die musterbasierte Trennung ist eine Datei mit Einträgen wie
Die Datei enthält in der Regel etliche tausend solcher Einträge. Diese
Einträge sind Wortbestandteile mit Zahlen zwischen einzelnen
Buchstaben. In den Zahlen steckt die Information darüber, ob an dieser Stelle
getrennt werden darf oder nicht, und welche Priorität diese Regel hat. Man
kennt solche Hilfen wie »Trenne nie st, denn es tut ihm weh.« (die inzwischen
ja nicht mehr gilt). So könnte man dieses Verbot mit s4t ausdrücken. Hier
bedeuten gerade Zahlen, dass nicht getrennt werden darf, ungerade Zahlen
erlaubte Trennstellen. Und je höher die Zahl, desto mehr Gewicht hat sie. Für
die Trennstelle bei Haus-tür könnte man mit einem zusätzlichem Muster haus5t
die obige Regel aufheben, da 4 kleiner ist als 5.
Die Vorgehensweise ist nun folgende. Wenn man ein Wort hat, für das man die
erlaubten Trennstellen ermitteln möchte, wandelt man es erst in Kleinbuchstaben
um und fügt vorne und hinten ein Wortbegrenzungszeichen ein, bei TeXs
Trennmustern ist das ein Punkt. So wird aus Autobahn ».autobahn.« Dann
probiert man alle Trennmuster durch, ob sie irgendwo in dieses Wort passen. In
diesem Beispiel sind das die Muster a2u, 1auto, 2u1t, uto1, 1to,
o1b, 3bah und 2hn. Die Zahlen lässt man für das Ausprobieren weg. Hier
werden die Muster an die passende Stelle unter das Wort geschrieben:
. a u t o b a h n .
--------------------------------------
a2u 2
1auto 1
2u1t 2 1
uto1 1
1to 1
o1b 1
3bah 3
2hn 2
--------------------------------------
Maximum
. a u t o b a h n .
1 2 1 0 3 0 2 0 0
Es wird also das Maximum aller Zahlen in einer Spalte gebildet und dann wird
das Wort wieder zusammengesetzt, im Beispiel also .1a2u1to3bah2n. Die Nullen
kann man einfügen, muss man aber nicht. Dann werden die geraden Zahlen
gelöscht: .1au1to3bahn. Dann werden alle ungeraden Zahlen durch
Trennmöglichkeiten ersetzt und die Punkte für die Wortbegrenzung weggelassen:
-au-to-bahn. Es sind also drei Trennstellen erlaubt: am Anfang vor dem Wort
(das ist natürlich Unfug und fällt weg), dann bei au- und to-.
Im nächsten Beispiel gibt es ein Muster mit einem Wortende und einmal einen Konflikt
zwischen a1d (Trennung erlaubt) und 2dc (Trennung nicht erlaubt):
. m ä d c h e n .
3mä 3
ä1d 1
2dc 2
d1ch 1
c4h 4
h2en. 2
Maximum
. m ä d c h e n .
3 2 1 4 2
Hier ist die einzige erlaubte Trennung zwischen d und ch. TeX wählt die Parameter so, dass die ersten drei Zeichen eines Wortes und die letzten beiden Zeichen nicht getrennt werden. Daher fällt die erste 3 bei dem letzten Beispiel weg.
Nachtrag 8.9.2016: auf github liegt ein in Go geschriebenes Programm, das den Algorithmus umsetzt.