
»boxes and glue« oder: TeX-Implementierung in Go
Meine Hauptentwicklung ist der speedata Publisher, eine Software für datenbasiertes Publizieren (database publishing). Die Basis dafür ist (Lua)TeX, ein Satzprogramm das bekannt für seine hohe Ausgabequalität ist (einen Überblick über die Architektur habe ich an einer anderen Stelle im Blog). Zwar ist LuaTeX eine moderne Weiterentwicklung von TeX, das mit OpenType Schriftarten und erweitertem Zeichensatz zurecht kommt, doch die Entwicklung des speedata Publishers mit LuaTeX stößt immer wieder an Grenzen.
Grenzen von LuaTeX
- Viele Probleme lassen sich nicht mit Bordmitteln von Lua lösen. Die Standardbibliothek von Lua ist sehr minimalistisch. Beispielsweise ist es nicht ohne Zusatzmodule möglich, eine https-Verbindung zu einem entfernten Server zu öffnen.
- Lua ist eine einfache Programmiersprache, die für kleinere Skripte sehr gut geeignet ist, jedoch keine Hilfsmittel für größere Projekte mit sich bringt. Als Beispiel sei hier nur Typsicherheit oder ein System für Abhängigkeiten externer Pakete genannt.
- Die Auswahl an in Lua geschriebenen Modulen ist sehr »übersichtlich«. Einen guten XML oder CSS-Parser sucht man z.B. vergeblich.
- Durch die Notwendigkeit von C-Bibliotheken für Lua ist es nicht einfach, Binaries für andere Plattformen zu erstellen (cross compiling).
- Den größten Teil von TeX benutze ich überhaupt nicht: die doch eher kryptische Eingabesprache ist für meine Zwecke nicht hilfreich.
Bisher erstelle ich für die benötigte Funktionalität eine große (dynamisch ladbare) Bibliothek. Diese Bibliothek kann ich dank Lua-FFI direkt als C-Bibliothek einbinden. Als Programmiersprache nehme ich Go, das auch im speedata Publisher an anderen Stellen genutzt wird (z.B. als Startprogramm sp, als REST-API Server etc.).
Warum überhaupt LuaTeX?
Neben dem Gemecker über LuaTeX sollte man nicht vergessen, welche großartige Leistung in TeX bzw. LuaTeX stecken.
- TeX besitzt einen hervorragenden Absatzumbruchalgorithmus, der aus einzelnen Wörtern einen Absatz mit mehreren Zeilen macht. Dieser Algorithmus berechnet den optimalen Umbruch anhand vielfältiger Kriterien. Z.B. kann eine schlechte Worttrennung am Ende eines Absatzes Einfluss auf die ersten Zeilen haben. Die Idee ist, dass im ganzen Absatz bestimmte nachteilige Formatierungen minimiert werden (Anzahl der Silbentrennungen, zu große Abstände zwischen Wörtern etc.).
- Die große Flexibilität von TeX hat eine große Zahl verschiedener Anwendungen hervorgerufen. Ursprünglich als Textprogramm für Donald Knuth’s Sekretärin bzw. für einen sehr engen Autorenkreis geplant, werden heute Briefe, Bücher, Bildbände, Kataloge und viele andere Dinge mit TeX (bzw. dessen Nachfolgerprogrammen) erzeugt. Diese Flexibilität leitet sich daraus ab, dass die alle druckbaren Einheiten (Bilder, Zeichen und andere Elemente auf der Seite) aus Kästchen bestehen, die mit schlauen Algorithmen beliebig verknüpft und ineinander geschachtelt werden können. Um diese kleinen Einheiten herum gibt es eine flexible Programmiersprache, mit der man beliebige Anwendungen erzeugen kann.
- Der Mathematiksatz (also das Aussehen von Formeln) sind immer noch von unerreichter Qualität. Viele Menschen kennen und nutzen TeX hauptsächlich für den Formelsatz. (Für den speedata Publisher ist das Thema eher von untergeordneter Rolle.)
- LuaTeX bietet erstmals einen direkten Zugriff auf alle TeX-Interna und ermöglicht komplexe Anwendungen mit verhältnismäßig einfacher Programmierung. Außerdem erbt LuaTeX die Fähigkeiten von PDFTeX und den Erweiterungen von Omega.
Erstes Fazit
Für mich ist es eine etwas blöde Situation. Zwar ist der speedata Publisher meine Software der Wahl, wenn ich Produktkataloge und ähnliche Dokumente für Auftraggeber erstelle, doch die Weiterentwicklung wird durch die Nachteile oben einfach schwerer gemacht als nötig. Aber auf die Ausgabequalität von (Lua)TeX mag ich nicht verzichten, das bestätigen mir auch immer wieder die Anwender. Aus diesem Grund experimentiere ich schon länger mit einer Neuimplementierung von TeX.
TeX neu implementiert
Nach reichlicher Überlegung (ich habe wirklich lange gegrübelt und experimentiert), bin ich zum Schluss gekommen, dass man den in Pascal geschriebenen Spaghetti Code (TeX) nicht sinnvoll direkt in eine andere Programmiersprache übersetzen kann. Es hängen hier zu viele Sachen drin, die einem die Übersetzung schwer machen.
- Hoch optimierte Datenstrukturen und Algorithmen sind sehr clever, aber für eine Wartbarkeit des Codes nicht hilfreich. Z.B. hat die Funktion, um die badness einer Zeile zu berechnen, folgendes Aussehen (Kommentare in geschweiften Klammern):
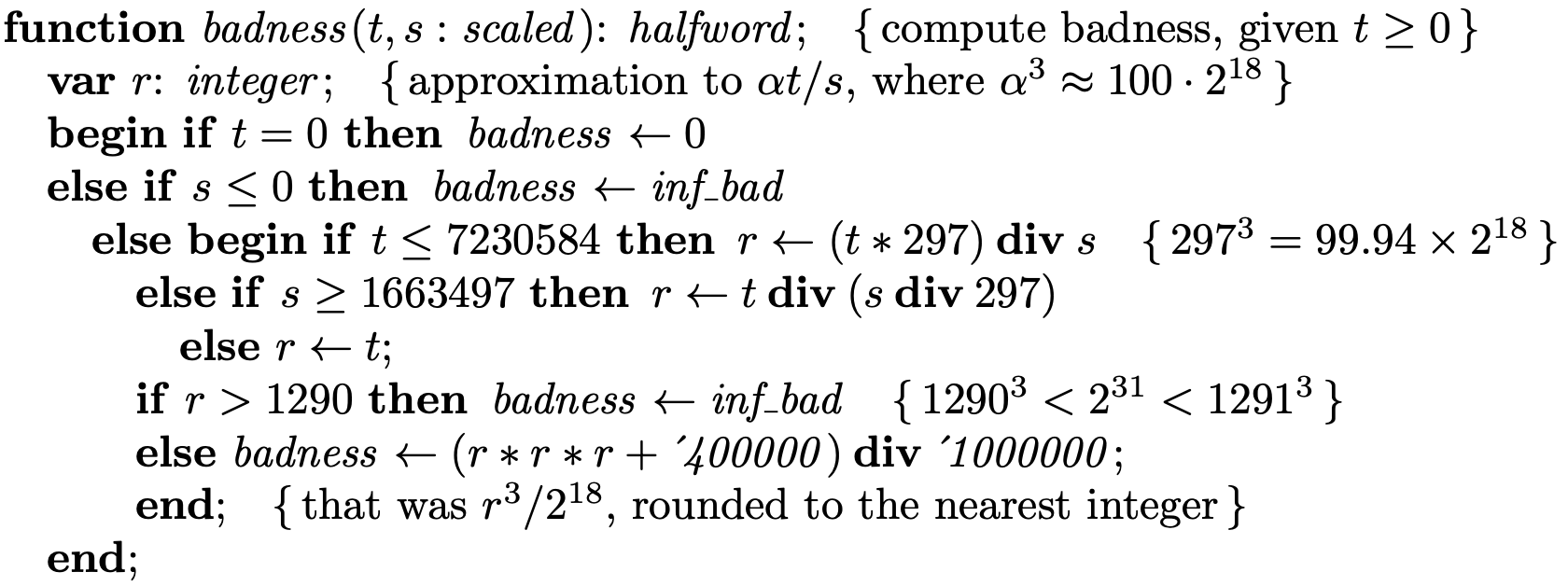
Die Funktion kann nur 1095 verschieden Werte errechnen. Das reicht zwar für alle praktischen Belange. Doch warum sollte man nicht die tatsächliche Formel 100(t/s)³ nutzen? Bei einer Neuimplementierung müsste man immer abwägen zwischen Kompatibilität mit dem ursprünglichen TeX bzw. einer vielleicht saubereren Implementierung, die man auch versteht, wenn man nicht tief im Code steckt.
- Die Eingabesprache ist sehr mit den Algorithmen verzahnt. Eine Trennung wäre wünschenswert, um das ganze modularer zu gestalten. Außerdem ist die Eingabesprache zwar mächtig, aber für viele Programmierer eher ungewohnt.
- Viele Gegebenheiten, die bei der Erstellung von TeX noch getroffen werden mussten, sind inzwischen hinfällig. Heutzutage gibt es allgemein standardisierte Fonts, es gibt Ausgabeformate wie PDF, die Ein- und Ausgabekodierung ist durchgängig UTF-8 (bzw. kann leicht umgewandelt werden). Auch Details wie die Gleitkommazahlen (floats) sind heute in den Programmiersprachen plattformübergreifend gelöst. Damit fallen viele Eigenheiten von TeX weg, für die es in den siebziger Jahren noch keine plattformübergreifende Lösung gab. Man muss diese Teilbereiche von TeX derzeit nicht mehr nach programmieren.
»boxes and glue«
In Anlehnung an die zwei besonderen Einheiten von TeX, den Kästchen (box) und den dehnbaren Leerräumen (glue), heißt meine Neuimplementierung von TeX »boxes and glue«. Sie befindet sich derzeit in Entwicklung. Als Programmiersprache nehme ich natürlich Go, die sehr einfach plattformunabhängige Binaries erzeugen kann. Ein paar Dinge zeichnen sich schon ab:
- Strenge Trennung zwischen Eingabe und Algorithmen. Derzeit sind bzw. werden TeXs Algorithmen wie Absatzumbruch, Silbentrennung und die Handhabung von Leerraum eingebaut. Da die Eingabesprache für mich eher zweitrangig ist, muss diese an einer anderen Stelle implementiert werden.
- Nutzung aktueller Textsatz-Techniken wie OpenType und TrueType fonts, UTF-8 Eingabe und PDF-Ausgabe bzw. plattformübergreifendes Vorhandensein von Gleitkommazahlen und Eingabe-/Ausgabemechanismen werden genutzt.
- Die grundlegenden Datenstrukturen (Nodes als kleinste Einheiten) werden ebenfalls benutzt, um alle Ausgaben zusammenzubauen.
Insofern kann die Implementierung eher als TeX-Bibliothek verstanden werden, die aus anderen Programmen her benutzt werden können. Da Go auch dynamische Bibliotheken (dll, dylib, so) erzeugen kann, lassen sich vermutlich aus jedem anderen Programm diese Satzfunktionen nutzen.
Designziele
Für mich sind eine Reihe von Dingen wichtig, die eine Satzengine haben muss.
- Ausgabequalität: TeX ist bekannt für die unübertroffene Ausgabequalität. Ich habe schon sehr viele Bibliotheken gesehen, die PDF erzeugen können. Doch bisher sind die wenigsten auch nur annähernd akzeptabel.
- Trennung von Eingabe und Satzmaschine. Für mich wichtig ist die Erzeugung von datenbasierten Dokumenten wie Kataloge, Datenblättern und ähnlichen Publikationen. Aber auch Dokumente aus HTML müssen erstellt werden können. Die Algorithmen sollen also unabhängig von der Eingabe funktionieren.
- Geschwindigkeit: TeXs Ausgabegeschwindigkeit ist sehr hoch. Auf einem alten Laptop (2015) kann LuaTeX ca. 300 Seiten / Sekunde ausgegeben. In dieser Größenordnung sollte sich die Bibliothek befinden. Aktuelle Benchmarks sind derzeit noch etwas schneller, das ist jedoch aufgrund der noch nicht vollständigen Implementierung nicht direkt vergleichbar. Es zeichnet sich aber ab, das auch hier die meisten Dokumente in weniger als einer Sekunde ausgegeben werden.
- Parallelisieren von Aufgaben. Moderne Prozessoren haben viele Kerne, die von den aktuellen TeX-Implementierungen nicht benutzt werden. Viele Algorithmen in TeX können parallel ausgeführt werden bzw. würden bei einer parallelen Berechnung eine Verbesserung bringen können. Absätze kann man parallel mit unterschiedlichen Parametern berechnen und das beste Ergebnis verwenden. In vielen anderen Bereichen können Arbeiten parallel ausgeführt werden (z.B. Silbentrennung, Erstellen von Subsets bei der Fonteinbettung, …)
- PDF-Standardkonformität: Ein Problem von TeX ist, dass zu Zeiten entwickelt wurde, wo PDF noch in weiter Zukunft lag. Zwar ist die Erweiterung PDFTeX bzw. LuaTeX in der PDF-Erstellung sehr flexibel (man kann beliebige PDF-Objekte erzeugen), dennoch ist es immer wieder eine häufig gestalte Frage, wie denn PDF/A-3 oder PDF/UA konforme Dateien erzeugt werden können. Dem Anwender soll es so leicht wie möglich gemacht werden, Standardkonforme Dateien zu erzeugen.
Stand der Dinge und Ausblick
Die Bibliothek »boxes and glue« kann schon Texte mit TeXs Umbruchalgorithmus umbrechen und als PDF-Datei erzeugen. Während einige Komponenten noch nicht vorhanden oder in Entwicklung sind, gibt es zumindest funktionierende Säulen, auf denen die Bibliothek steht:
- Fontloader: Die Bibliothek kann OpenType und TrueType Schriftarten laden und in das PDF als Subset einbetten. Langfristig soll das durch Harfbuzz abgelöst werden.
- Node-Handling: Die kleinsten Einheiten von TeX (glyph, glue, hbox, vbox, …) können mit Inhalten gefüllt und verknüpft werden. Außerdem gibt es die Möglichkeit, v/hboxen mit bestimmten Breiten zu erzeugen.
- Externe Bilder: Es können externe Bilder in den Formaten JPG, PNG und PDF eingebunden werden.
- Beliebige Objekte (vertikale Listen mit Inhalten) können an beliebiger Stelle ausgegeben werden. Eine Output-Routine wie bei TeX/LaTeX ist nicht Teil des Backends und muss für die Anwendung speziell geschrieben werden.
Eine etwas detaillierter Sicht auf die Architektur der Bibliothek gibt es unter https://github.com/speedata/boxesandglue/discussions/2.
Wie geht es weiter?
Die Entwicklung läuft auf Basis des Programms xts, einem experimentellen Klon des speedata Publishers. Hier füge ich die Funktionalität nach und nach zur Software hinzu, bis im Idealfall eine reine Go-Implementierung desselben Funktionsumfangs mit derselben hohen Ausgabequalität entstanden ist. Hier wird natürlich immer entschieden, ob die Bibliothek »boxes and glue« oder das aufrufende Programm erweitert werden muss.
Weiterhin soll die Bibliothek auch in anderen Zusammenhängen benutzt werden, z.B. als Bibliothek für die PDF-Ausgabe in größeren Programmen, die eine TeX-vergleichbare Satzqualität benötigen.
Hier geht es zum Quellcode: https://github.com/speedata/boxesandglue